

By James Dieteman
Director of Adversary Pursuit, Managed Services
In this age of default detections and behavioral analytics, many consider the challenge of threat detection a solved problem. Detections, however, are anything but solved. And embracing this truth is a first step toward providing your organization, or your customers, with better protection.
I could write volumes about the perspectives and practices of the ECS security operations center (SOC) detection engineering team. This brief article will introduce you to just a few.
JAMES DIETEMAN
Four-time winner of DEF CON’s Black Badge

Default Detections Need Tuning
In the face of tightening budgets and limited investment, many organizations rely on default or built-in detections in much of their security stack, assuming that vendors provide at least a baseline of capabilities. But relying on defaults is just as dangerous within a security stack as it is within most pieces of deployed technology in the enterprise.
Vendors’ coverage claims notwithstanding, most existing detections require significant tuning to be effective. This may be due to overbroad logic generating an avalanche of detections for analysts to investigate, or logic tuned so tightly it can identify only activity identical to some previously seen attack. Either way, relying on just these basics is untenable. If you’re going to invest in SIEM technology, invest in the surrounding infrastructure and support staff too.
Learn how advanced tuning of threat detection rules
can help you navigate a sea of threat alerts.
Centralized Management and Detection as Code
In modernizing our operations, we’ve transitioned to managing detections centrally. This may seem a minor point, but the move has yielded major benefits for our SOC and our customers.
Simplicity and Order
Before this transition, managing detections across all our customers’ SIEMs, environments, and tech platforms was complex and confusing.
Managing all this within a single SIEM and a single organization is doable. But when you have different environments running different versions of detections with different logic, different exceptions, and different levels of risk acceptance, it’s no longer possible for analysts to respond quickly, consistently, and accurately. Documentation can help, but with the speed of today’s security operations and changing organizational needs, you need a dedicated analyst just to keep the documentation current.
By using a central repository, we can push tested rules across all supported environments as soon as our tweaks or updates are made. We’re no longer concerned about stragglers being forgotten or accidentally omitted from a checklist. Successful pushes are there for all to see. Changes to logic, exceptions, and tunings are timestamped and tracked. We can direct customer questions to the person responsible, and the necessary documentation can live alongside the logic itself.
Platform Migration Ease
A centralized platform for detections also makes migration from one security platform to another easier, especially in cases where automated detection translation tools are offered or can be created. As budgets change, prices fluctuate, and the security product market moves to adapt, being able to support more than a single platform can help keep vital partnerships thriving.
Detection Rule Sharing
Finally, when we identify malicious activity in one customer environment, we can share the detections and activities we respond with across all covered environments. If a particular piece of ransomware has turned up for one customer, there’s no reason detection rules looking for similar activity shouldn’t be shipped to other, yet unaffected SIEMs. Forewarned is forearmed.
A Way to Measure Coverage
In discussions about detections, data sources, and SIEMs, customers often ask, “How covered am I?” This is not an easy question to answer. We answer it by leveraging the old standby, the MITRE ATT&CK framework.
The framework is generally used in the reverse — to map observed attacks back against the tactics, techniques, and procedures (TTPs) involved. Using the framework to evaluate coverage, however, has helped us identify benchmarks and provide measurably improved protection, as well as an answer to that common customer question.
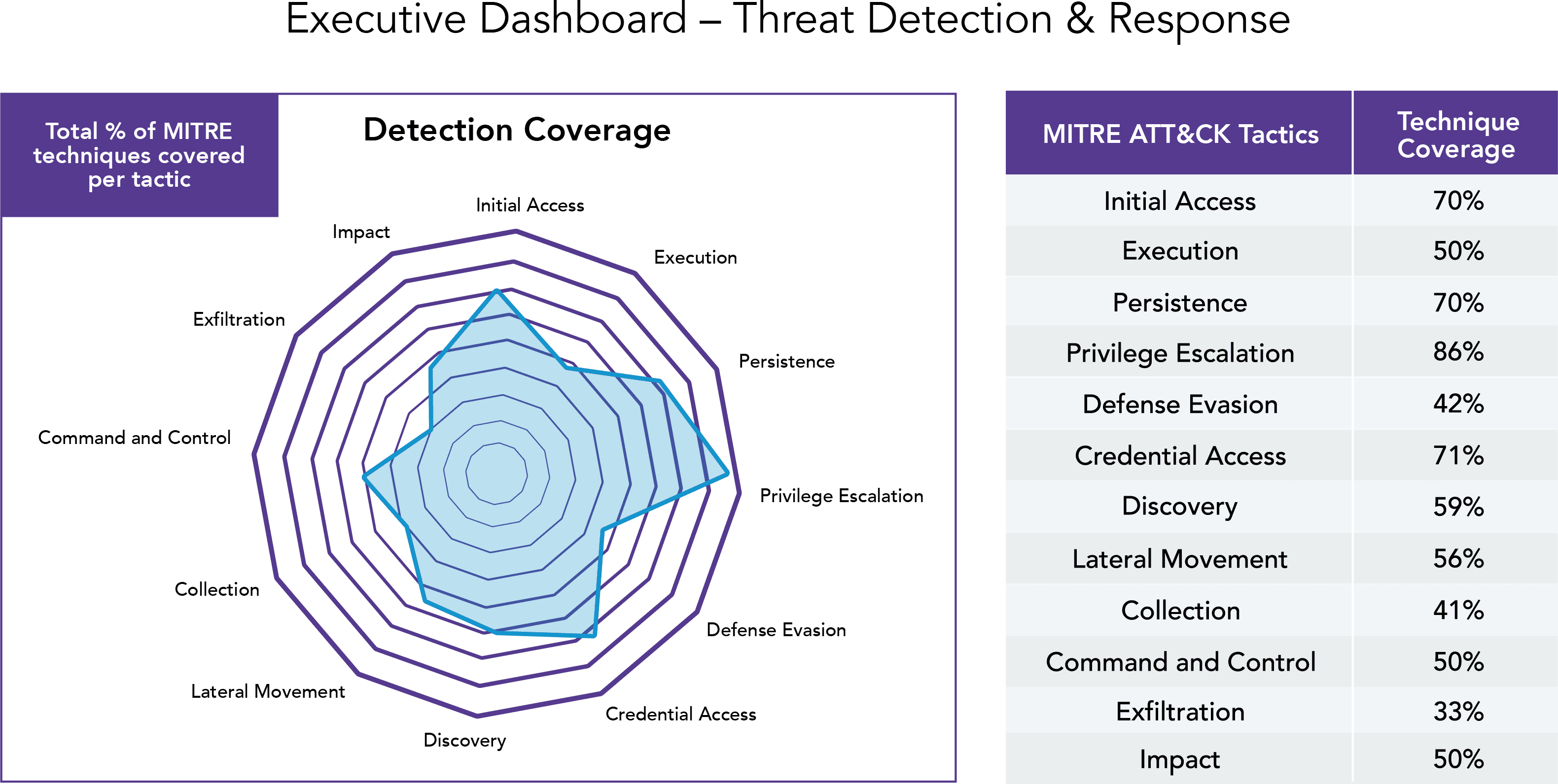
This graph shows an ECS customer’s coverage percentage for each MITRE ATT&CK TTP category. It doesn’t show the whole picture, but it’s a useful snapshot that provides fundamental metrics.
Of course, not all tactics and techniques are created equal. For example, putting detections in place for reconnaissance activity generally results in large quantities of non-actionable noise. And trying to track resource development independent of initial access is a fool’s errand. This is where having a strong intelligence team can mean the difference between playing at mere table stakes and really winning big.
In working with our intelligence team, we identify the TTPs that are prevalent not just in the industry, but also across our customers’ verticals and among those who are targeting our customers. Through our work in both the federal and commercial sectors, we watch segments of cyber terrain unseen by many and thereby have a broad view of prevalent TTPs. We’re able to prioritize based on what’s out there now and what’s likely to come, never on gut feeling.
Hear more from our cybersecurity experts about
how intelligence drives security.
Sound Detection Engineering Is Key
Tight budgets, the ease of believing that default detections are sufficient, and other factors prevent many from investing in detection engineering. This article only scratches the surface of the perspectives and practices our detection engineering team leverages to improve the protection we offer. While detections are not yet a solved problem, they’re certainly a surmountable one.
Tags:



