

At ECS, we’ve gathered the best minds in technology to design, develop, and deploy solutions that address our customers’ most complex problems. The ECS Cloud Center of Excellence assembles architects, analysts, and practitioners who speak fluent “cloud.” For cloud professionals working with Amazon Elastic Cloud Compute, automated backups are an important housekeeping task. In this #ECSTechTalk post, cloud architect Hitesh Pandya takes practitioners through the process step by step.

By Hitesh Pandya
Sr. Cloud Architect, AWS Certified Architect (Professional)
One of the benefits of cloud computing is that it empowers the customer to perform tasks easily in an automated, scripted fashion—but with great power comes great responsibility.
In order to ensure the environment is well managed, there must be a constant effort to do housekeeping tasks to clean up unrequired artifacts and resources generated by these tasks. One such activity is to take regular backups of Elastic Cloud Compute (EC2) instances, which is akin to taking backups of a personal computer drive. In cloud terminology, the drive is called an Elastic Block Storage (EBS) volume.
Two of the possible ways to implement backups of your EC2 instances on AWS are:
- If your instance is EBS-backed, you can create the snapshots of the EBS volume.
- You can create an Amazon Machine Image (AMI) of your instances as a backup solution.
An EBS snapshot is a point-in-time copy of the blocks that have changed since the previous snapshot, with automatic management to ensure that only the data unique to a snapshot is removed when it is deleted. This incremental model reduces costs and minimizes the time needed to create a snapshot.
The EBS snapshot and the AMI are stored on Amazon Simple Storage Service (S3) which is known for being high durability and highly reliable.
Along with the joy of backups comes the additional task of managing the snapshots. As usual, the solution lies in leveraging tagging to categorize, organize, and manage the snapshots.
Typically, the task of creating and managing snapshots has been performed using AWS Command Line Interface (CLI), through the AWS Console or using the AWS SDK.
To simplify the creation, retention, and deletion of Amazon EBS volume snapshots, AWS introduced the Data Lifecycle Manager in July 2018. Instead of creating snapshots manually and deleting them in the same way (or building a tool to do it for you), you simply create a policy, indicating (via tags) which volumes are to be snapshotted, set a retention model, fill in a few other details, and let the Data Lifecycle Manager do the rest. The Data Lifecycle Manager is powered by tags, so begin by setting up a clear and comprehensive tagging model for your organization.
Creating and Using a Lifecycle Policy
Data Lifecycle Manager uses lifecycle policies to figure out when to run, which volumes to snapshot, and how long to keep the snapshots around. You can create the policies in the AWS Management Console, from the AWS Command Line Interface (CLI) or via the Data Lifecycle Manager APIs; Here is a walkthrough of creating a Data Lifecycle Management policy via the Console.
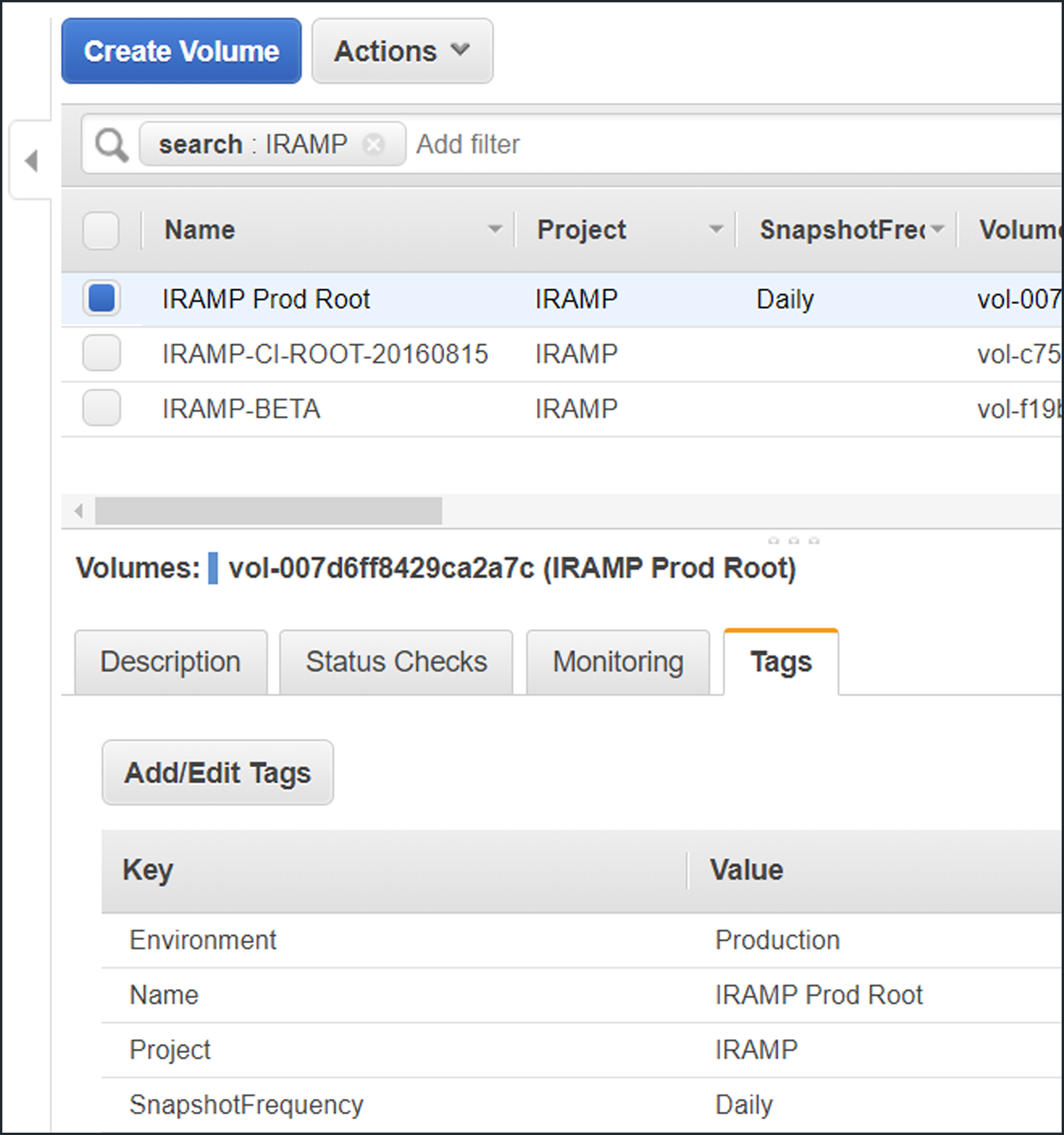
Here are my EBS volumes, all suitably tagged with a Project and SnapshotFrequency.
Note! Tag key and value are case sensitive.
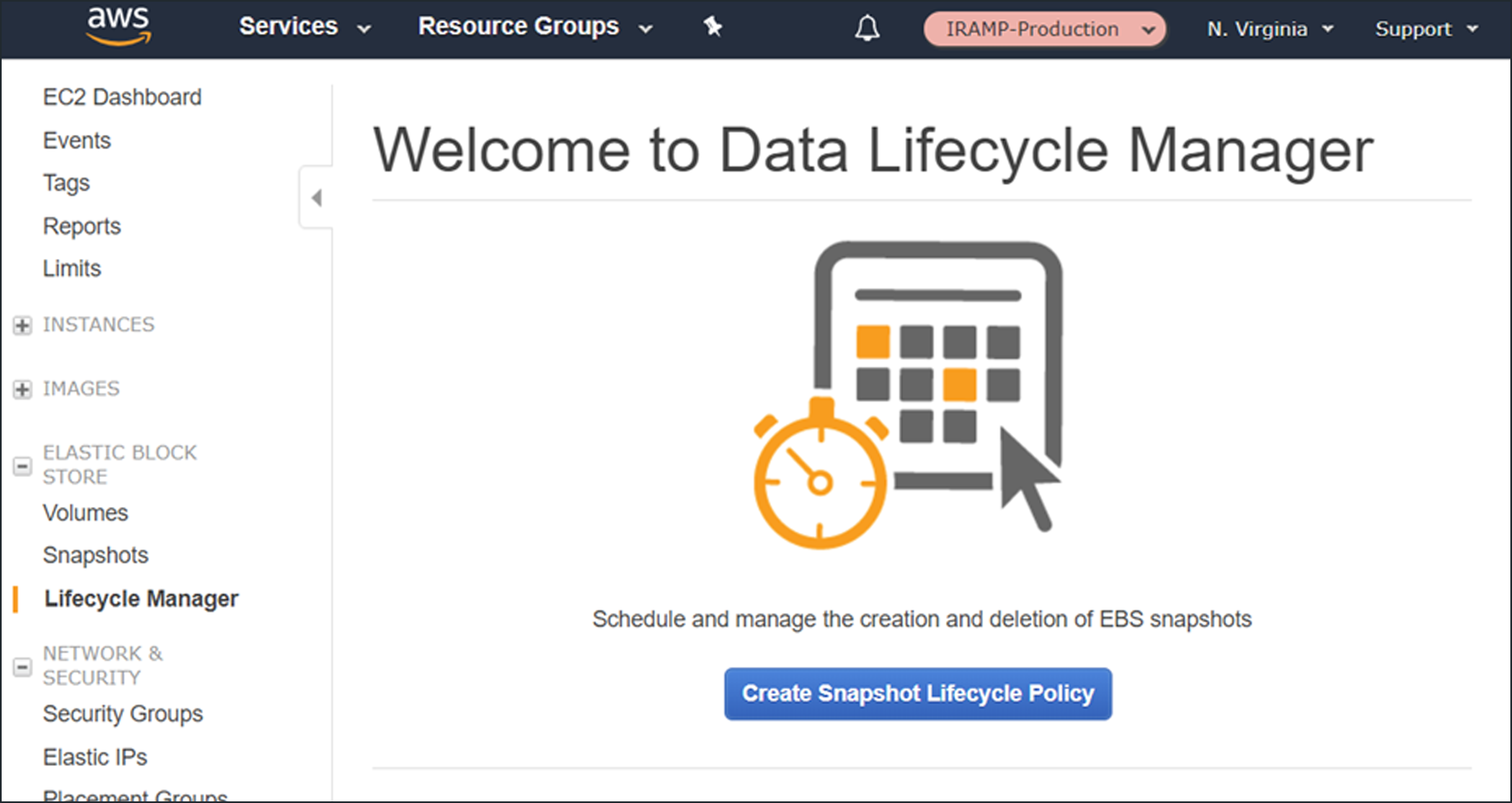
Access the Lifecycle Manager from the Elastic Block Store section of the menu, then click Create Snapshot Lifecycle Policy to proceed:
Then I create my first policy:
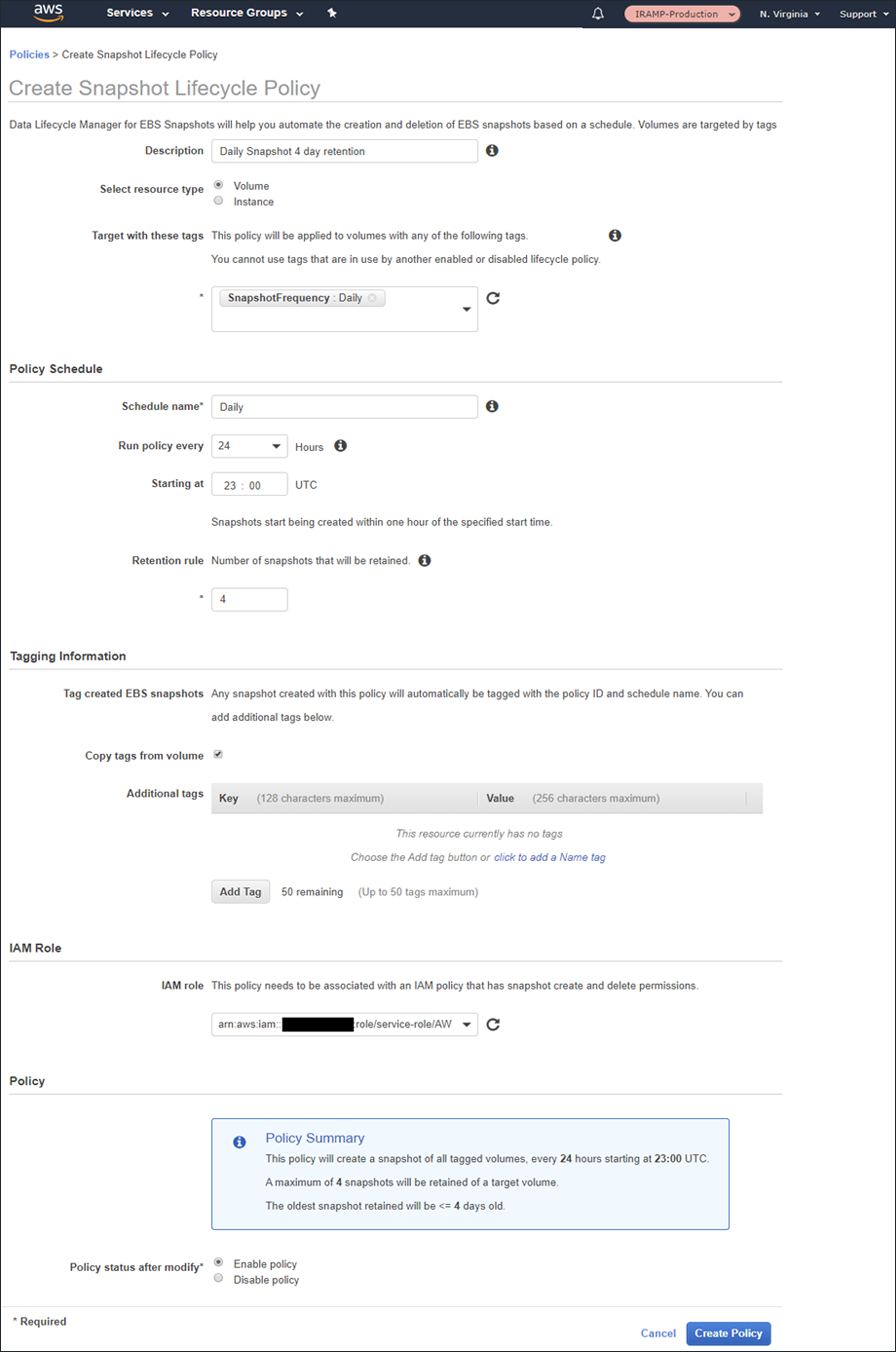
Use tags to specify the volumes that the policy applies to. If we specify multiple tags, then the policy applies to volumes that have any of the tags.
You can create snapshots at 12- or 24-hour intervals and can specify the desired snapshot time. Snapshot creation will start no more than an hour after this time, with completion based on the size of the volume and the degree of change since the last snapshot.
You can use the built-in default (Identity Access Management) IAM role or can create one of your own. If you use your own role, you’ll need to enable the EC2 snapshot operations and all the DLM (Data Lifecycle Manager) operations; read the docs to learn more.
Newly created snapshots will be tagged with the aws:dlm:lifecycle-policy-id and aws:dlm:lifecycle-schedule-name automatically. You can also specify up to 50 additional key/value pairs for each policy.
All of the policies at a glance:
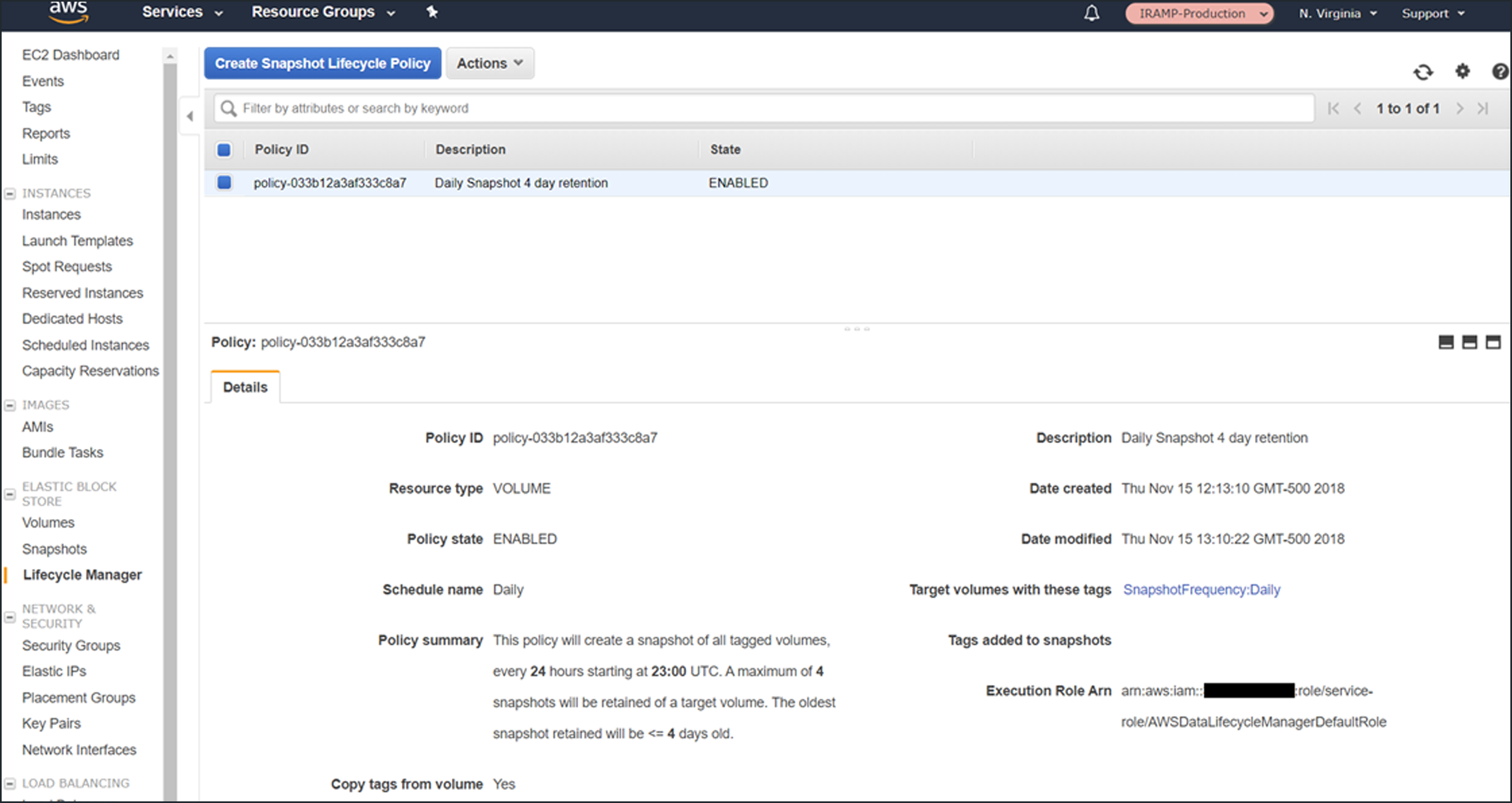
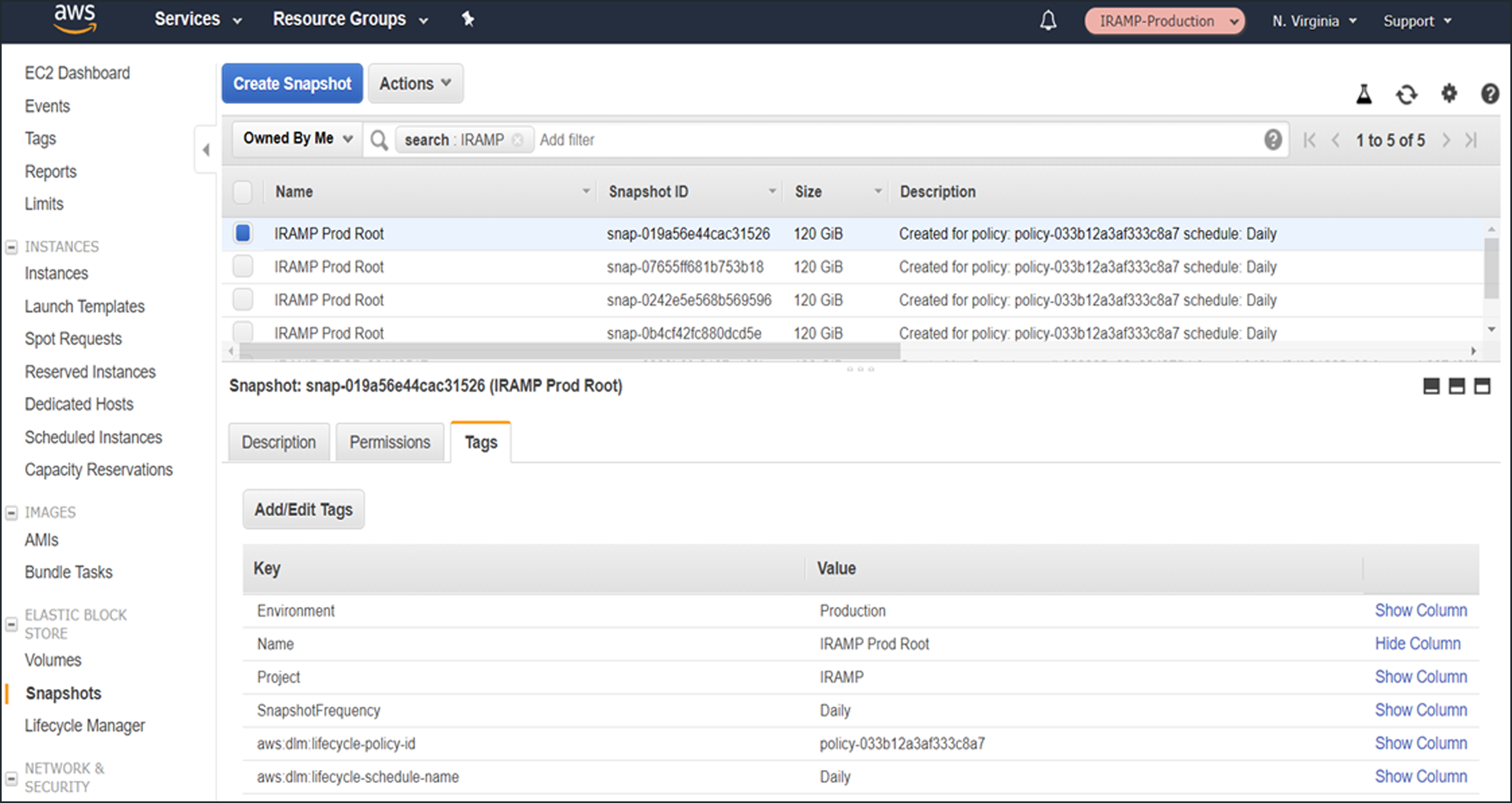
A screenshot of the snapshots that had been created after two days, as expected:
Things to Know
Here are some things to keep in mind when you start to use Data Lifecycle Manager to automate your snapshot management:
Data Consistency – Snapshots will contain the data from all completed input/output (I/O) operations, also known as crash consistent.
Pricing – You can create and use Data Lifecycle Manager policies at no charge; you pay the usual storage charges for the EBS snapshots that it creates.
Availability – Data Lifecycle Manager is available in the US East (N. Virginia), US West (Oregon), and Europe (Ireland) regions.
Tags and Policies – If a volume has more than one tag and the tags match multiple policies, each policy will create a separate snapshot and both policies will govern the retention. No two policies can specify the same key/value pair for a tag.
Programmatic Access – You can create and manage policies programmatically! Take a look at the CreateLifecyclePolicy, GetLifecyclePolicies, and UpdateLifeCyclePolicy functions to get started. You can also write an AWS Lambda function in response to the createSnapshot event.
Error Handling – Data Lifecycle Manager generates a “DLM Policy State Change” event if a policy enters the error state.


